

Introduction:
Hyperparameter tuning is an essential step in machine learning that involves selecting the best values for the parameters of a model. Hyperparameters are the parameters that are not learned by the model during training but instead must be set manually. Examples of hyperparameters include the learning rate, regularization strength, and the number of hidden layers in a neural network. The performance of a model can be significantly improved by finding the optimal values for these hyperparameters.
In this blog post, we will discuss different techniques for hyperparameter tuning in machine learning, including grid search and cross-validation. We will also provide sample code in Python using the scikit-learn library.
Grid Search:
Grid search is a simple and widely used method for hyperparameter tuning. It involves creating a grid of hyperparameter values and evaluating the model on each combination of values in the grid. The optimal hyperparameter values are then selected based on the performance of the model.
Here is an example of grid search in Python using scikit-learn:
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
param_grid = {'C': [0.1, 1, 10, 100], 'kernel': ['linear', 'poly', 'rbf', 'sigmoid']}
svc = SVC()
grid_search = GridSearchCV(svc, param_grid, cv=5)
grid_search.fit(X, y)
print("Best parameters: ", grid_search.best_params_)
print("Best score: ", grid_search.best_score_)
In this example, we are using the GridSearchCV class from scikit-learn to perform a grid search over the hyperparameters C and kernel for an SVM classifier. The parameter grid specifies four values of C and four values of kernel, resulting in a total of 16 combinations. The cv parameter specifies the number of folds to use in cross-validation.
The fit method is used to train the model and evaluate it on each combination of hyperparameters. The best_params_ attribute returns the hyperparameter values that result in the highest cross-validation score, while the best_score_ attribute returns the corresponding score.
Cross-Validation :
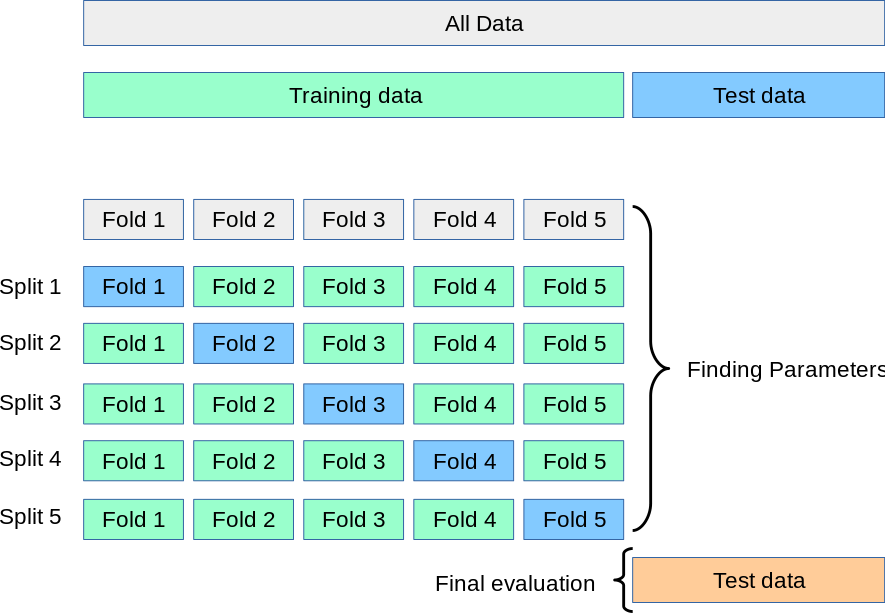
Cross-validation is a technique used to evaluate the performance of a model and to select the best hyperparameters. It involves splitting the dataset into multiple folds, training the model on some folds, and evaluating it on the remaining fold. This process is repeated for each combination of hyperparameters, and the average score across all folds is used to select the best hyperparameters.
Here is an example of cross-validation in Python using scikit-learn:
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
svc = SVC(C=1, kernel='linear')
scores = cross_val_score(svc, X, y, cv=5)
print("Cross-validation scores: ", scores)
print("Average score: ", scores.mean())
In this example, we are using the cross_val_score function from scikit-learn to perform a 5-fold cross-validation on an SVM classifier with C=1 and kernel='linear'. The function returns an array of scores for each fold, which are then averaged to obtain the overall score.
Hyperparameter Tuning in Random Forest Classifier using GridSearch CV:
Here's an example of how to perform hyperparameter tuning on a Random Forest Classifier using Grid Search CV in Python using scikit-learn.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# Load the iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Define the parameter grid to search over
param_grid = {
'n_estimators': [50, 100, 200, 500],
'max_depth': [5, 10, 15, 20],
'max_features': ['sqrt', 'log2']
}
# Create a Random Forest Classifier object
rfc = RandomForestClassifier()
# Create a Grid Search object
grid_search = GridSearchCV(rfc, param_grid, cv=5)
# Fit the Grid Search object to the data
grid_search.fit(X, y)
# Print the best parameters and best score
print("Best parameters: ", grid_search.best_params_)
print("Best score: ", grid_search.best_score_)
In this example, we are using the iris dataset and a Random Forest Classifier to classify the iris species. We define a parameter grid to search over, which includes the number of estimators, the maximum depth of the trees, and the maximum number of features to consider when splitting nodes. We create a Random Forest Classifier object and a Grid Search object, passing the classifier object and the parameter grid as arguments to the Grid Search object. We then fit the Grid Search object to the data, which trains and evaluates the classifier on all possible combinations of hyperparameters. Finally, we print the best parameters and best score obtained by the Grid Search object. These parameters and score can be used to build the best Random Forest Classifier model for this problem.
Conclusion:
Hyperparameter tuning is a critical step in machine learning that can significantly improve the performance of a model. Grid search and cross-validation are two popular techniques for hyperparameter tuning, and scikit-learn provides convenient tools for implementing these techniques in Python. By using these techniques, machine learning practitioners can find the best hyperparameters for their